Readings |
Assignments |
(1) Data Science for Business, Chapter 1; (2) Hadley Wickham on R Data Structures; (3) OpenTechSchool’s Introduction to Data Processing with Python (4) Data Structures; (5) Intro to Pandas |
Lab 1 Due |
Presentation
Getting Started with Data
The capacity for our society to generate, manage, and use data is incredible. Data lays at the foundation of any analytics based process. Without the ability to effectively assess, manage, and interact with data there is little we will be able to do from an analytics perspective.
The ability to make informed decisions regarding data and all the accompanying processes is a key role of the data scientist. Almost everyone has been touched through someone that they know which has had cancer. It is an extremely devastating disease and disease and I apologize if this discussion being any negative memories to recall.
But think about the variety of ways we might view cancer. We might think of cancer as a boolean variable that is true or false based on a diagnosis. But how many false are really true and undetected verses the reverse? One can code the type, severity, and location of the cancer as they are still properties of the individual, but how does one code potential relations with cancer or the reported eating habits of the patient. As one dives deeper, the entire genetic code could be relevant or the actual image of the cancer itself, like the one shown above. Images, genes, networks, and behaviors are just data, but as we ask and answer questions of the world we must eventually link and manage the data in a way that can be meaningfully analyzed.
THE CRISP PROCESS MODEL

Data is the foundation of all analytics processes, but our thinking of how to store and organize data has shift with technology and with the amount of data required to store and analyze. There are different types of data structures that vary significantly based on their application.
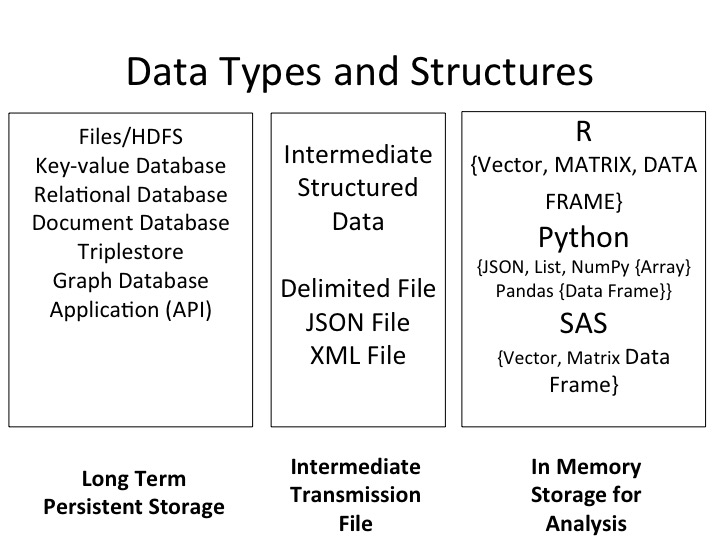
Long Term Persistent Storage
The first is the long term persistent storage solutions that store data on an ongoing basis. The most common method is through a database management system. While databases used to be primarily relational tables and SQL, they have evolved to meet the varying needs of scale and the applications in which they are deployed. There are key-value, relational, document, triplestore, and graph style database that each provide application relevant specific structures and procedures to map, store, select and extract data for their applications. Let’s go over two of the most common persistent storage types.
Relational Databases. The most frequent paradigm in IT related system is the relational database. Databases have enabled the robust organizational and web systems that the cohesive flow of products and services in our society. Modeling the data within these systems is typically complex, and database management systems (DBMS) have within them structured tables and structured query language (SQL) to connect with the tables. These tables individually are matrixes are connected by keys in such a way that they can incorporate the complex nested relationships of objects.
The relational database provides application designers with a way of ensuring consistency while minimizing redundancy. It accomplishes this by separating the data into different tables through a process called normalization. Consider the following example. A customer order is likely to contain multiple different products. Each of these products are similarly likely to have inventory, prior shipments, reviews, etc. In order to minimize the redundancy, many product details are included in a product table and then just linked to other tables through the productID key. This productID key provides think link to show. That way, if there is a change in the name of the product, all applications showing different parts of the workflow would be instantly updated.
It also means that as data scientists looking to do an analysis of products frequently purchased together one would first have to connect data from a variety of tables. This process of denormalization using SQL is outside the scope of this book.
Document Oriented Databases. The relational database practice of normalization has a number of limitations, however, and document oriented databases have moved in to provide an alternative.
One limitation of the relational model is it doesn’t fit very closely with the object oriented model of programming that has grown to dominate the creation of applications. While software packages called called object relational mappers make this process nearly automatic, there is still some complexity in this translation. In addition, it turns out that as databases scale the process of connecting tables through keys becomes a much more time consuming process.
As a result, having the capability to store related information in a single place, even if it involves some redundancy, can be a reasonable tradeoff for application developers. In particular, MongoDB has emerged in the past 5 years as a real competitor when storing a wide variety of data meant to be presented in web based applications. Rather than linked tables, data is stored in objects which may have a reasonably complex internal hierarchy based on JavaScript Object Nation, which is further discussed below.
Application Programming Interfaces. For many online sources of data-such as Facebook, LinkedIn, & Twitter, the database structure is hidden from the enduser. These sites provide Application Programming Interfaces (APIs) that provide standard ways for programmers to authenticate and interact with the applications in different ways. In many cases, APIs allow both write access to read access to site, enabling developers to create complex applications that work seamlessly with the original. When working with APIs, data scientists often store the extracted data locally in a file or DBMS so that it can be accessed.
Files and Big (Often Unstructured) Data. Files are a persistent storage mechanism that works just as well as on your own operating system. Files can be accessed but there is no additional functionality for things like the selection, indexing, and structure that database management systems provide, and as a result file based storage methods traditionally have not scaled well.
This has changed though in the context of big data storage that has been optimized to do complex analyses on unstructured data. When people talk about “big data,” the majority of the time they are referring to something in the Hadoop ecosystem. Hadoop was birthed at Yahoo, an open source implementation of the Map Reduce algorithm originally developed by Google. At it core, Hadoop was generated for the web–highly unstructured data that had to be processed. The Hadoop Distributed File System (HDFS) at the core provides a way of storing files in large quantities and the various tools in the Hadoop ecosystem facilitate accessing and processing these files to generate meaningful results.
Each of these methods of storing and retrieving data each could require separate courses. For now, we will assume that you have managed to extract the data into some type of intermediate file format.
Intermediate File Structures
Whether you are accessing data from a database, API, or HDFS infrastructure, in many cases you will select the appropriate data and work with it locally for further analysis. This is going to be our entry point to doing data understanding and data preparation.
Flat Files. Files are an extremely common way of interacting with datasets, with comma delimited files being the most common. Delimited files can be thought of as a structure of a Excel document. Data within each row is separated by the delimiter. The delimiter serves to separate the variables and give it structure. When organized like the example below the data can be easily be opened by programs like Excel or a Google spreadsheet.
Consider the following data from the Titanic Kaggle Assignment.
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
9,1,3,"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)",female,27,0,2,347742,11.1333,,S
10,1,2,"Nasser, Mrs. Nicholas (Adele Achem)",female,14,1,0,237736,30.0708,,C
Notice how text fields are encoded with quotes. This ensures that if the string has a comma in it there isn’t a problem with parsing the document.
Javascript Object Notation.While the flat file is probably the easiest model to work with when loading data, it has some limitations. The most important one is that it does not have a way of capturing nested data structures. Javascript Object Notation (JSON) has emerged as the dominant standard for transmitting data from document/key-value data stores as well APIs. JSON translators are available for any programming language and can easily input the associated structure into memory.
{
"firstName": "Jane",
"lastName": "Doe",
"address": {
"streetAddress": "1 North Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumbers": [
{
"type": "home",
"number": "555-111-2222"
},
{
"type": "mobile",
"number": "555-121-1212"
}
],
}
Let’s also look at how our titanic data would work with transmitted through JSON.
{
"1": {
"Survived":"0",
"Pclass":3,
"Name":"Braund, Mr. Owen Harris",
"Sex":"male",
"Age":22,
"SibSp":1,
"Parch":0,
"Ticket":"A/5 21171",
"Fare":7.25,
"Cabin":"",
"Embarked":"S"
},
"2": {
"Survived":"1",
"Pclass":1,
"Name":"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",
"Sex":"female",
"Age":38,
"SibSp":1,
"Parch":0,
"Ticket":"PC 17599",
"Fare":71.2833,
"Cabin":"C85",
"Embarked":"C"
},
"3": {
"Survived":"1",
"Pclass":3,
"Name":"Heikkinen, Miss. Laina",
"Sex":"female",
"Age":26,
"SibSp":0,
"Parch":0,
"Ticket":"STON/O2. 3101282",
"Fare":7.925,
"Cabin":"",
"Embarked":"S"
},
"4": {
"Survived":"1",
"Pclass":1,
"Name":"Futrelle, Mrs. Jacques Heath (Lily May Peel)",
"Sex":"female",
"Age":35,
"SibSp":1,
"Parch":0,
"Ticket":"113803",
"Fare":53.1,
"Cabin":"C123",
"Embarked":"S"
},
"5": {
"Survived":"0",
"Pclass":3,
"Name":"Allen, Mr. William Henry",
"Sex":"male",
"Age":35,
"SibSp":0,
"Parch":0,
"Ticket":"373450",
"Fare":8.05,
"Cabin":"",
"Embarked":"S"
},
"6": {
"Survived":"0",
"Pclass":3,
"Name":"Moran, Mr. James",
"Sex":"male",
"Age":null,
"SibSp":0,
"Parch":0,
"Ticket":"330877",
"Fare":8.4583,
"Cabin":"",
"Embarked":"Q"
}
}
Notice how each of the values are nested within the PassengerId field. This gives a nested relationship to dye data.
In Memory Storage for Analysis
When using any programming language, there are both embedded and custom data structures that can be implemented by external packages used in these languages. These specific characteristics of how data is handled within the programming environment are unique to the languages, meaning that Python, R, and SAS could (and in sometimes do) handle things differently. At its core though all data are objects and thus their behavior is governed by underlying classes.
In the Lab, are going to focus on the most common type of data structures for doing data science using R, Python, and SAS and how to go about the process of importing data. In each case, we will start by describing a bit to get started in using the language.
Photo Credits
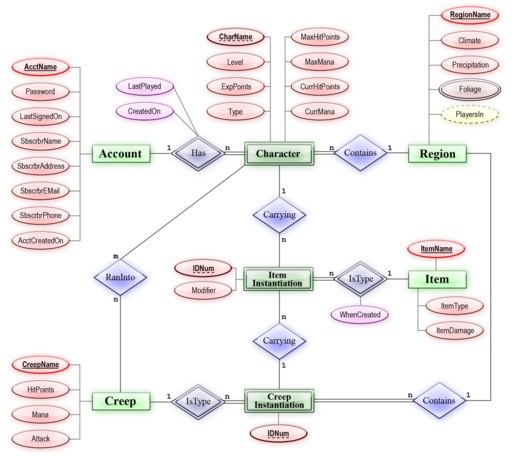
ER Diagram
https://upload.wikimedia.org/wikipedia/commons/7/72/ER_Diagram_MMORPG.png
Header photo by Yale Rosen
Mucoepidermoid carcinoma, high grade Case 200
https://www.flickr.com/photos/pulmonary_pathology/6499879267